Adatbázisok tervezése
Az adatbázisok helyes megtervezése kulcsfontosságú a logikus felépítés, és a helyes működés és érdekében. A tervezés során ezért be kell tartani néhány szabályt, amelyet normálformáknak neveznek. Ezeket példákon keresztül ismerjük meg. Kezdjük egy egyszerű példávan, egy iskola tanulóinak nyilvántartásával! Elsőként gondoljuk végig, milyen adataikat szeretnénk rögzíteni, példánkban ez legyen a tanulók neve, életkora és az, hogy az illető melyik osztályba jár.
Lehet a tanuló neve kulcsmező? Mivel elképzelhető, hogy egy iskolába több azonos nevű tanuló is jár, ezért a válasz nem. Ahhoz viszont, hogy egy tetszőleges tanuló sorát egyértelműen meg tudjuk határozni, kulcsmezőre lesz szükségünk; enélkül nem tudnánk megkülönböztetni őket. Megoldás lehetne pl. az egyes tanulók szemályi számát is rögzíteni, de ennek felhasználhatóság jogi szempontból aggályos, ezért egy általános módszert használunk, a mesterséges kulcs képzését. Ez példánkban annyit tesz, hogy a tábla egyes sorait sorszámokkal látjuk el. Mivel így a az egyébként azonos nevű tanulók sorszáma eltérő lesz, és nem lesz két, azonos sorszámmal rendelkező sorunk, minden tanulót meg tudjuk különböztetni egymástól. Ez a gyakolatban azt jelenti majd, hogy nem Szabó Annára, hanem a az 5-ös id-jű (azonosítójú) sorra hivatkozunk.
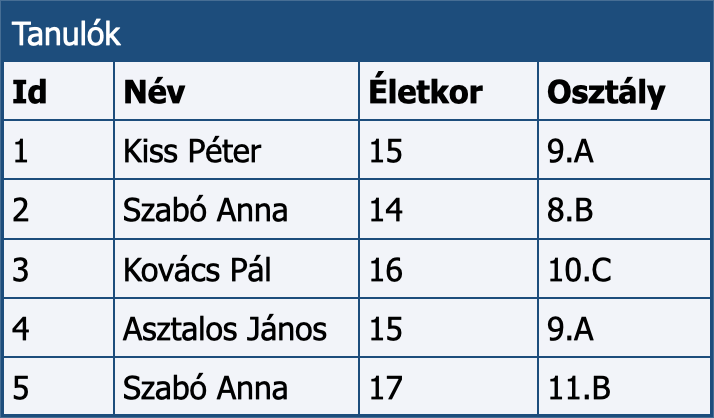
Egy iskola tanulóinak adatai.
Relációk
Az adatbázisok táblái között kapcsolatok is definiálhatók, innen ered a relációs adatbázis elnevezés. Egy komlex adatbázis értelemszerűen sok, különböző típusú adatot tartalmazhat, melyet már nem tárolhatunk egyetlen táblában. Ezért több táblát építünk fel, és a köztük levő összefüggéseket a kapcsolatokkal fogjuk leírni. Lássuk ezt egy példán! Tartsuk nyilván az egyes osztályok osztályfőnökeinek nevét is úgy, hogy tudjuk: egy tanár több osztály osztályfőnöke is lehet. Az eddigiek alapján a kézenfekvő megoldás az alábbi lehetne:
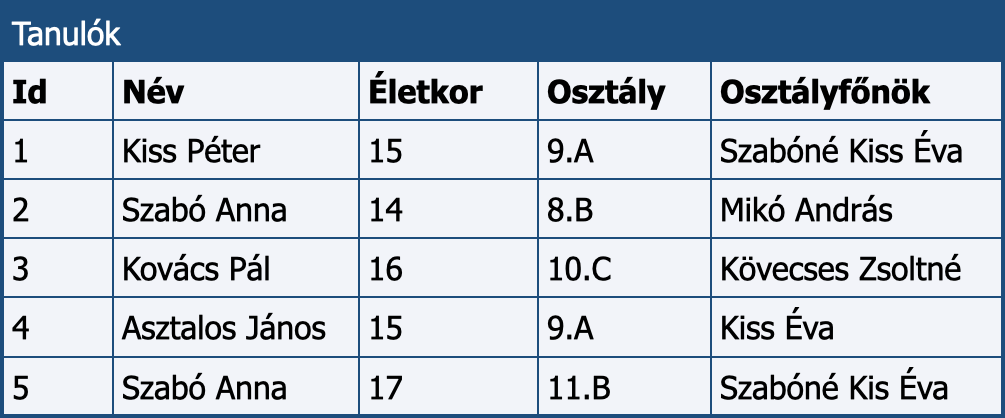
Az osztályfőnökök nevei ismétlődnek.
Ez a felépítés felvet egy problémát, melynek következménye az adatbázis inkonzisztenciája lesz. Az adatok tárolása során ugyanis az osztályfőnökök nevének különböző formában történő írásával nem tudjuk majd eldönteni, hogy ugyanarról a személyről van-e szó. A fenti tábla feltehetően hibás, mivel az adatbevitel során Szabóné Kis Évát egyszer egy s-sel, mákor kettővel írták. Persze ez akár két különböző személy is lehet. Kiss Éva szintén lehet azonos ezzel a személlyel (pl. ha közben férjhez ment Szabóhoz). Az ilyen dilemmák az adatbázis hibás tervezésére utalnak, melynek elkerülésére egy általános módszert kell alkalmazni.
Ez példánkban az osztályfőnökök és a tanulók szétválasztása, és egy logikai kapcsolaton keresztüli összekötése lesz, mellyel az adatbázisunk már nem egy, hanem két táblát tartalmaz majd az alábbi felépítésben:

Az osztályfőnökök kiemelése
A megoldásban létrehozunk egy új táblát Osztályfőnökök néven, melyben az egyszerűség kedvéért most csak a nevüket fogjuk tárolni. A már ismert névazonosság lehetősége miatt itt is gondoskodni kell az egyes személyeket megkülönböztethetőségéről, ezért azokat most is egy mesterséges kulccsal, a sorszámozással érjük el. Így, még ha lenne is két azonos nevű tanár az iskolában, egyértelműen meg tudjuk majd őket különböztetni.
Hogyan kell „olvasni” ezt a két táblát? Egy tanuló sorában az Osztályfőnök_ID-hez érve egy számot találunk. Ez azt jelenti, hogy az osztályfőnök adatait nem itt írtuk le, hanem egy másik tábla meghatározott sorszámú sorában (hogy melyikben, azt a struktúrába nem kell leírni). Amikor tehát itt tehát egy 1-es érték szerepel, az azt jelenti, hogy a további adatokat (az Osztályfőnökök) tábla 1-es sorszámú sorában kell keresni (a fenti ábrán ezek a piros színű nyilak).
Ez alapján látható, hogy Kiss Péter, Asztalos János és a 11.B-be járó Szabó Anna osztályfőnöke is az 1-es sorszámú Szabóné Kis Éva. A 8.B-s Szabó Anna sorában az Osztályfőnök_ID értéke 2, ezért az ő osztályfőnöke az Osztályfőnökök tábla 2-es számú sorában szereplő Mikó András.
A kapcsolatok kiépítése során az adatbázis egyes tábláiban szereplő rekordokat másokkal kötjük össze. A példánkban az osztályfőnököket hozzárendeltük a tanulókhoz, ezzel tudtuk egyértelművé tenni, hogy melyik tanuló melyik tárgyból milyen jegyet szerzett.
Kérdések:
Hogyan változtatná meg az adatbázist, ha Kovács Pál osztályfőnöke is Mikó András lenne? (Válasz: A
Tanulóktábla 3-as sorában aOsztályfőnök_IDértékét át kell írni 2-re.)Szabóné Kiss Éva egy hónapja elvált, és újra Kiss Éva a neve. Hogyan aktualizálja az adatbázist úgy, hogy minden tanuló esetén érvényes legyen a változás? (Válasz: Az
Osztályfőnököktáblában az 1-es sorban kell a nevet aktualizálni. Mivel a többi tanuló soraában szerelőOsztályfőnök_IDugyanide „mutat”, ezért ez a javítás elegendő.
A kulcsokról
Már említettük, de az eddigi példákban is látható volt, hogy egy tábla minden egyes rekordjának egyedinek kell lennie, ezért annak valamilyen kulcsmezőt kell tartalmaznia. A kulcs a rekord olyan adata, amely az egész rekordot egyértelművé teszi, más szavakkal, amely ismeretében a rekord egyértelműen azonosítható.
Egy ember esetében nem lehet kulcs a neve, hiszen vannak azonos nevű emberek. Ugyanígy: a születési idő sem lehet az, mert egy napon több ember is születik. Személyek azonosítására pl. a személyi szám lehet használatos, mert az mindn ember esetében eltérő, a neme mellett a születési időből és egy azon belüli sorszámból áll. A személyi igazolvány száma éppúgy lehetne kulcs, de nem ideális, mivel azt időről-időre cserélik, így nem állandó.
Gépjárművek esetén az alvázszámot szokás kulcsként használni, mivel az autó rendszáma, akár motorszáma is változhat, de a váza sosem cserélődik.
Termékek esetében a gyári szám lehet egyértelmű azonosító, de számos szervezet képez saját, egyedi számot az azonosításra, ilyen pl. a leltári szám.
A fenti példákban arra törekedtünk, hogy találjunk egy olyan tulajdonságot, ami az adott rekord egyediségét biztosítja. Mivel nem minden esetben van ilyen, ezért sokszor a tervezés során mi magunk hozunk létre kulcsot például a rekordok már látott sorszámozásával. Az identifier szóból származó ID megnevezés épp ezt írja le, egy azonosító mezőt jelent.
Egy kulcs tehát lehet természetes (alvázszám, sorozatszám) és lehet mesterséges. A természetes kulcsok eleve adottak, a mesterségeseket pedig az egyértelműség kedvéért (vagy a dolgunk megkönnyítése érdekében) magunk hozzuk létre.
A kulcs azonban nem mindig egyetlen mezőből áll, azaz nem mindig egyszerű kulccsal dolgozunk. Vannak esetek, amikor csak két, vagy több mező együttese azonosít egy rekordot, egy elvi példa erre egy könyv esetében a szerző és a könyv címe. Mivel egy szerzőnek több könyve is lehet és különböző szerzők írhatnak azonos című könyveket, ezért csupán a cím alapján nem lehet meghatározni, hogy melyikről is van szó. Az ilyen kulcsok neve összetett kulcs.
A fenti példákban a tanulók és osztályfőnökeik közti kapcsolatot úgy teremtettük meg, hogy a Tanulók táblában az osztályfőnököt azonosító kulcsot helyeztük el, mellyel a rekord egy másik tábla egyik rekordjának kulcsmezőjét tartalmazta. Mivel ez tehát egy egy másik tábla másik rekordjának kulcsa, ezért ezt idegen kulcsnak nevezzük.
A CDTár adatbázis
Alkalmazzuk a tanultakat egy összetettebb adatbázis megtervezése során, mellyel a CD lemezeink nyilvántartását szeretnénk megvalósítani! A feladatot végiggondoltuk, és (az egyszerűség kedvéért) a zenekarok nevét és alapítási évét, az albumok címét és az azokon levő számok címeit a lemezen levő sorrendben szeretnénk rögzíteni. Az első megoldásunk pl. így nézhetne ki:
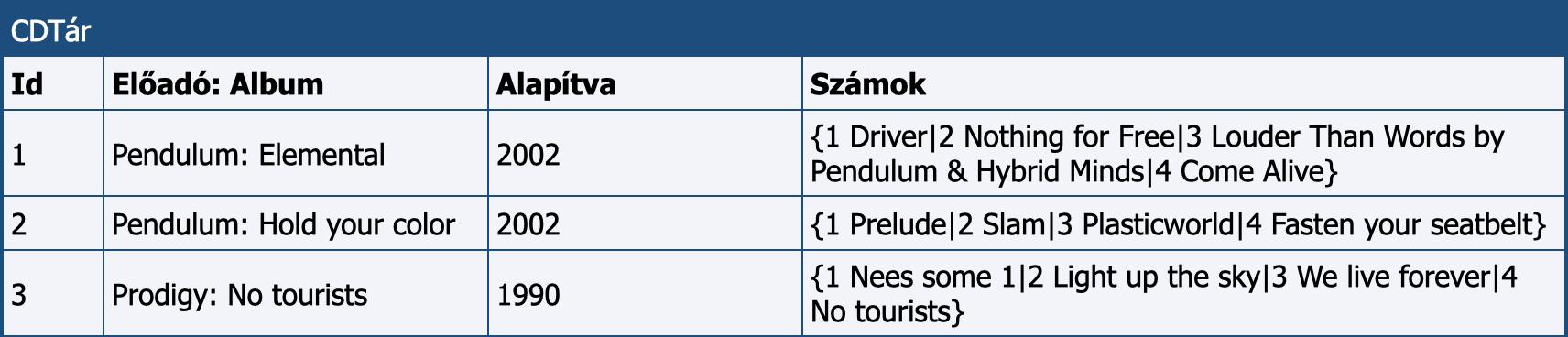
A CDTár első változata
Ez a megoldás sajnos több sebből vérzik. Az első, és legnagyobb hiba, hogy olyan mezőket is tartalmaz, melyekben nem egy „elemi” adat van, hanem több adatot is tárol valamilyen struktúra szerint. Ilyen az Előadó: Album és a számok felsorolását tartalmazó Számok is. Az adatok ilyen tárolása a gondos tervezés első szintjét sem éri el, még az ún. első normálformában sincs. Első lépésként ezektől kellene megszabadulnunk. Az egyszerűség kedvéért most a számokat egy kicsit félretesszük, és csak az előadókkal és az albumokkal foglalkozunk. Nincs más dolgunk, mint ezt a két adatot két önnálló oszlopban elhelyezni így:
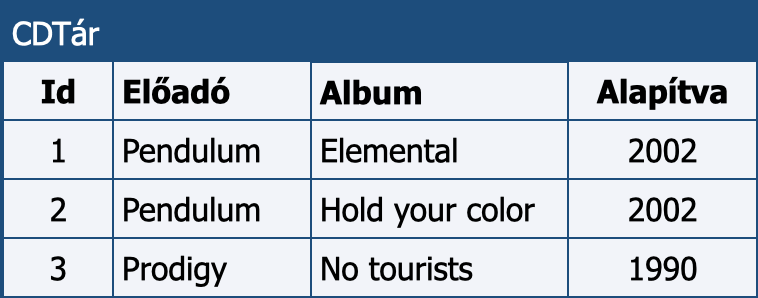
Szétválasztjuk az összetett adatokat.
A szétválasztás számos helyen megjelenik az adatbázisok tervezése során. Gondoljuk pl. egy cím megadására egy webshopban! Az irányítószám, a város, a közterület neve, típusa, a házszám, emelet, ajtó, lépcsőház megannyi mező szokott lenni. A neveket előtagra, vezetéknévre, középső névre és utónévre bontják.
Bár a tábla most már határozottan „jobban néz ki”, feltűnhet, hogy a zenekar neve és alapítási éve ismétlődik az egyes albumok esetén. Ahogyan az előző példa Osztályfőnök oszlopával kapcsolatban már láttuk, ezek az ismétlődések kerülendők, ezért ezeket az adatokat ki kellene emelni a táblából. Ezt úgy csináljuk, hogy az összetartozó adatokat azonos táblában hagyjuk, a kpacsolódóakat pedig egy másikban. Az előadóhoz tartozik az alapítás éve, hiszen egy előadóhoz csak egy ilyen tartozik. Az albumhoz viszont csak közvetetten tartozik a előadó, mert egy előadónak több albuma is lehet. Ezért a szétválasztást az alábbi ábrán látható módon végezzük:
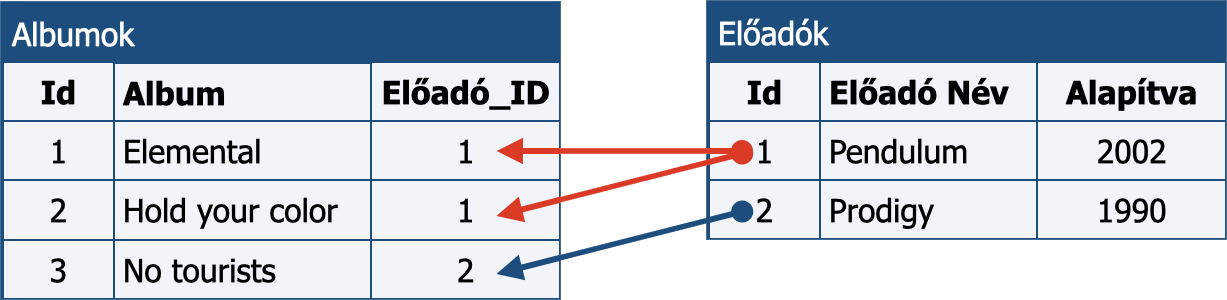
Előadók és albumok
Ebben, mivel egy előadót több albumhoz is hozzárendelhetünk, az egyes albumok soraiban az előadó azonosítóját, az Előadó_ID-t tároljuk, melynek értéke az Előadók táblában szereplő Id értékével egyezik meg. A fenti ábrán az 1-es Előadó_ID a Pendulum zenekart, a 2-es pedig a Prodgy-t azonosítja. (Mivel az egyes albumokhoz csak egy Előadó_ID-t rendelünk, az olyan lemezeket, amelyeknek több előadója van, nem tudjuk megfelelően tárolni.)
A szétválasztással elértük, hogy minden szükséges adat csak egyszer kerül rögzítésre, és annak geváltoztatása minden, arra hivatkozó helyen is érvényesülni fog.
Végezzük el ugyanezt az egyes lemezen található számokkal is! Ehhez először is meg kell szüntetni az összetett adattárolást, tehát az eredeti változatban használt, egy mezőben történő felsorolást kell módosítanunk. Kézenfekvő megoldás az „egy szám egy sor” de hogyan tároljuk a számok sorrendjét és azt, hogy melyik előadóhoz vagy albumhoz tartozik? Nos, az elv ugyanaz lesz, az egyes számok mellett feltüntetjük, hogy az hányadik szám az adott albumon, és egy másik hivatkozással pedig azt, hogy melyik albumon található. Az átszervezést az alábbi ábra szemlélteti.
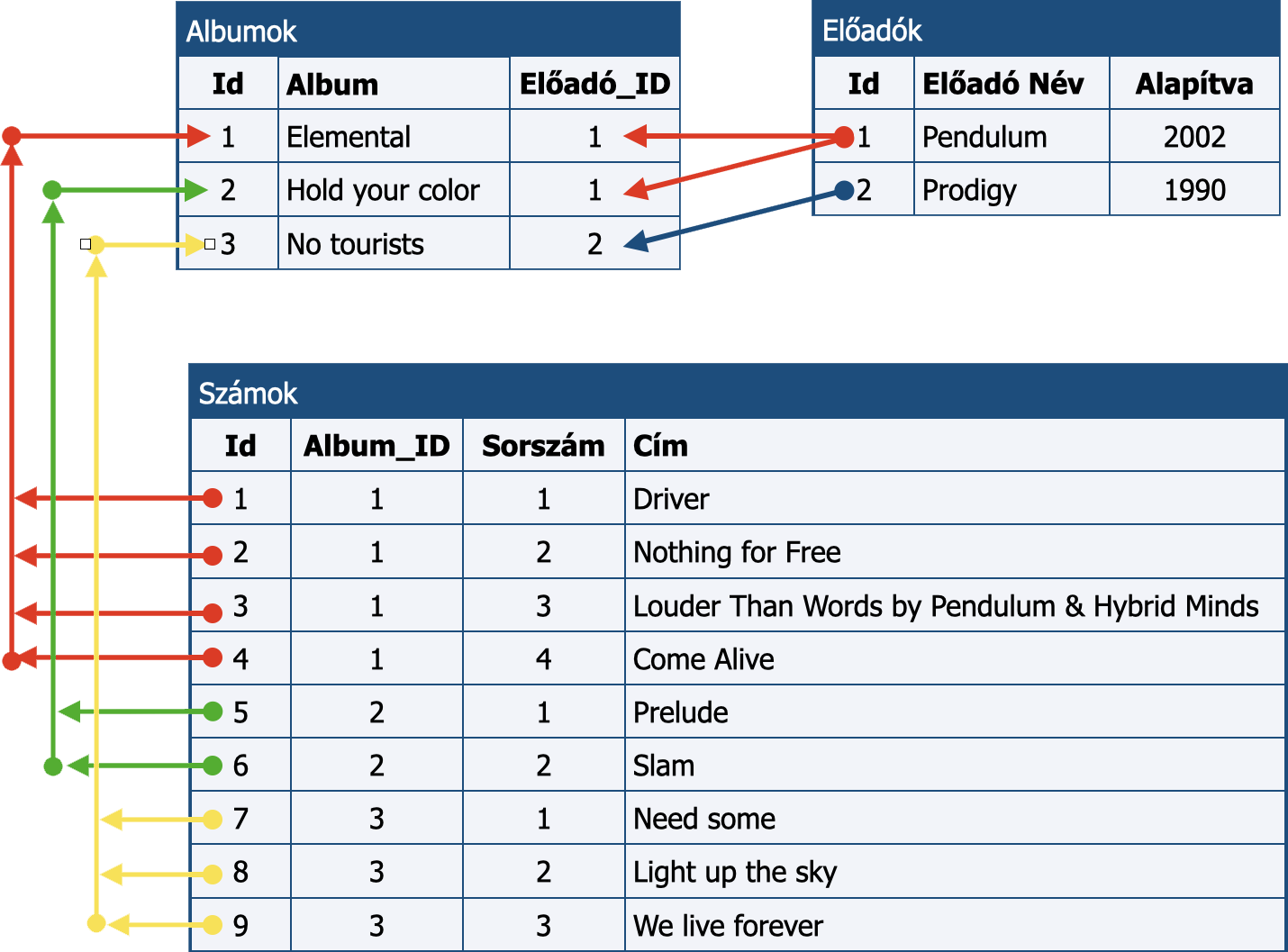
A zeneszámok tárolása az albumra hivatkozással történik.
Miért nem tároljuk az egyes számok esetén a zenekar aonosítóját is? Elsősorban azért, mert a számok csak közvetve, az albumon keresztül kapcsolódnak a zenekarhoz. A egy számhoz tartozó zenekar meghatározása ezért két lépésben történik. A Nothing for free Album_ID mezőjében 1-es szerepel. Az Albumok tábla 1-es sorszámú sorában az Előadó_ID értéke szintén 1, ez azonosítja a zenekart, melynek nevét az Előadók tábla 1-es sorában szereplő Előadó Név mezőből lehet kiolvasni (Pendulum).
Feladatok
Tervezd meg egy könyvtár
KönyvekésSzerzőktábláit! Elégedj meg azzal, hogy egy könyvnek egy szerzője lehet!Tervezd meg étterem adatbázisát, melyben az egyes ételek nevét (húsleves, tökfőzelék, almás pite) és és árát, valamint azok kategóriáit (levesek, készételek, desszertek) tároljuk!
Tervezd meg a filmek adatbázisát! Minden film esetében tárolni szeretnénk annak címét, rendezőjét és műfaját (kaland, romantikus, sci-fi)!
Egy webshopban számítástecnikai termékek adatbázisát kell megteveznünk. Tervezd meg a termékek tárolásának módját úgy, hogy azok különböző kategóriákba tartoznak (egerek, monitorok, ssd-k stb.) és tervezz egy kosarat, amelybe az adott vevő a megvásárolni kívánt termékeket tudja berakni.
Több-Több kapcsolatok
Az eddigi példákban helyenként kompromisszumot kellett kötnünk, a CD adatbázis esetében egy albumnak csak egy előadója lehetett, a könytáros példában pedig egy könyvnek csak egy szerzője. Ezt azért fogadtuk el, mert a megismert tárolási módszerünk, az ún. egy-több kapcsolat csak ezt teszi lehetővé, azzal, hogy a kapcsolat leírására egyetlen számot használunk, csak egy összeköttetést hozhatunk létre, igaz, ilyen kapcsolatot nem csak egy rekord esetében írhatunk le. Ennek eredményeként jöttek létre az egy előadó több albuma, vagy a több szám egy albumon jellegű kapcsolatok. De hogyan tudunk leírni több-több kapcsolatokat?
Nézzük meg ezt a CDTár példáján! Ha egy zenekarnak több albuma is lehet, és egy albumhoz több előadó is tartozhat, azt több-több kapcsolattal írhatjuk le. Ennek megvalósításához egy újabb, köztes táblára van szükség, mely tulajdonképpen két egy-több kacsolatot ír le. Lássuk ezt az alábbi ábrán!
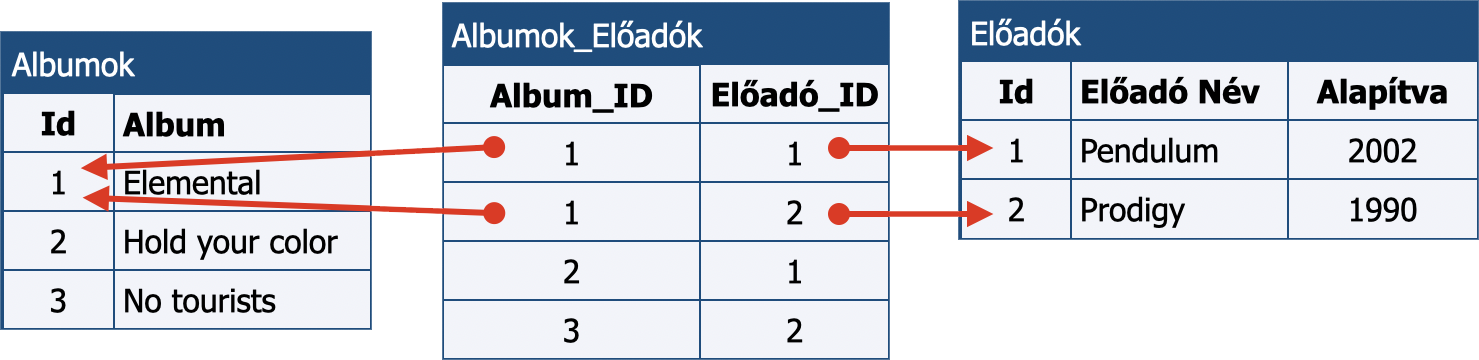
Több-több kapcsolat az előadók és az albumok közt.
Először is, az albumok táblából töröltük az Előadó_ID mezőt, erre így nem lesz szükségünk. A létrehozott kapcsolótábla nevét általában a két összekapcsolt tábla nevéből szokták képezni, innen az Albumok_Előadók elnevezés. A kapcsolótáblák általában két oszlopot tartalmaznak, mellyel az egyes kapcsolatokat írják le úgy, hogy a többszörös kapcsolatok leírására több sort használnak. A fenti példában az 1-es sorszámú, Elemental című albumhoz két előadó kapcsolódik, a Pendulum és a Prodgy is. A kiolvasásának gondolatmenete a következő:
Keressük meg a kérdéses album ID-jét!
Keressük meg a kpacsolótábla azon sorait, ahol az
Album_IDa keresett id-vel azonos!Határozzuk meg az ezen rekordokban szereplő
Előadó_ID-ket!Soroljuk fel az előadók neveit az
Előadóktáblából az Id-k alapján!
Feladatok:
Tervezd meg egy könyvtár
KönyvekésSzerzőktábláit úgy, hogy egy könyvnek több szerzője is lehessen!Felhasználók és szerepkörök adatbázisát akarjuk elkészíteni. Minden felhasználónak van bejelentkezési neve, jelszava és (valódi) neve, a szerepkörök közt pedig létrehozás, szerkesztés és törlés szerepel. Egy felhasználóhoz több szerepkör is rendelhető.